
Achieve Merger & Acquisition through Data Integration

Merger & Acquisition: an increasing trend that requires Data Integration
When a company decides to grow its market or its size, either an organic or external growth are envisioned. Over the last decade, Merger and Acquisition (M&A) in pharma industry has lived an incredible boom. The M&A process, from Acquisition Strategy to Implementation is quite well described in the literature. Nevertheless, some of those steps need a particular attention. At least the two following steps are critical regarding data exploration & integration:
- Due diligence step: during this phase, it is important for both parties to validate data integrity, quality & relevance. At this stage, the buyer wants to ensure that the acquired data is relevant enough to evaluate strengths and weaknesses.
- Implementation step, or how to integrate data in the information system. This key step often leaves people helpless because they are not equipped to meet the challenge.
Merger & Acquisition: What happens to data?
Unfortunately, the scientific data is often the poor relation that has been ignored for too long.
At this point, there are a few questions:
- Does the data cover all the needs?
- Is the available data meaningful?
- How can I have an overview of all the available data?
- What is the data about?
- How can I find in this new dataset the information to provide to the FDA?
Dexstr recently faced two situations where it is critical for the acquirer to be able to master the volume of new acquired data.
- 1st was in a case of a licensing In. The challenge was to recover 3 million of scientific data files and extract from this dataset the data requested by the FDA in order to release 2 vaccines on the market.
- 2nd, was a M&A situation. In that case, the most important is to be able to, first identify what the data is about and second, integrate the data in the acquirer’s information system.
In both situations, it is important to be reactive to deliver in time the relevant information either to the regulatory authority or to the management.
Merger & Acquisition: Entity detection to the rescue
From our experience, a solution to efficient Merger & Acquisition process at data level is to identify key entities and create a semantic annotation engine. This will speed up the acquisition of data that are usually mainly files, stored in file share, USB drive or at best Content Management system.
In practical terms, we might run into two different analyses on the data:
- On one hand we can start by trying to detect all the known entities in the data, this should help us to identify commonly used terms. This can be achieved using public ontologies dedicated to life science (disease ontology, PubChem, commercial drug names, company names, dbpedia, …). This process is known as Known Entity Detection.
- On the other hand, we work on all remaining keywords that appear statistically and specifically on those data, that are not known entities. We manually resolve them as “custom entities” (internal project codes, internal compound codes, name of key stakeholders or scientists, …). This process is known as Custom Entity Detection.
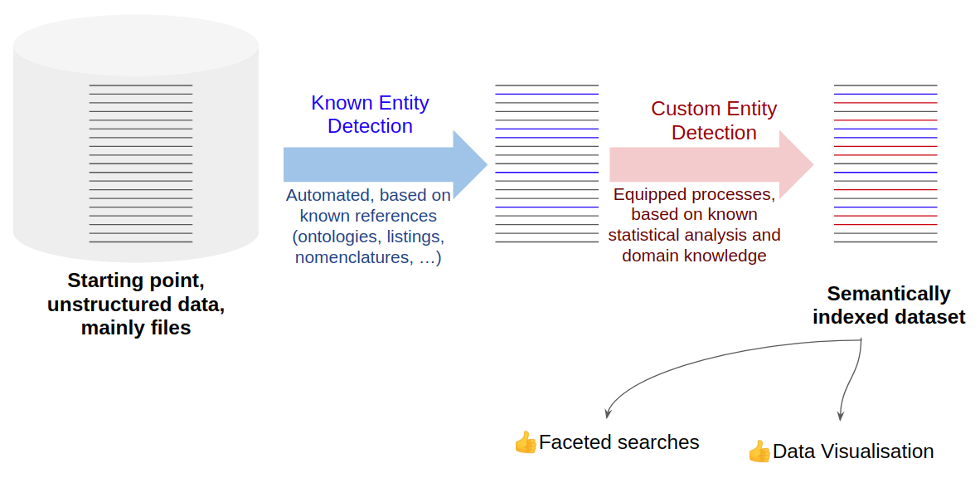
These two strategies are fast and do not really depend on the data volume as they are processed either automatically or based on aggregated data.
However, those tasks require subject matter experts involved in resolving the specific terms as entities.
Merger & Acquisition: Looking for a needle in a haystack
Thanks to the faceted search, based on entity detection, important documents, like analysis certificate of this specific batch in this specific project or results of this kind of experiment can be found in minutes!
This can help at multiple levels:
- During the acquisition process to assess the data completeness thanks to data visualisation.
- Following the acquisition, while the purchased compound will be submitted to approval.
In both situations, time is key and having the data already annotated with key information is a decisive advantage.
Merger & Acquisition: Toward an efficient use of the Acquisition
Beside the benefits of getting the right documents in crucial periods, there is also a desire to integrate the new data from the purchase to the internal existing data.
Here again, having the files annotated with meaningful entities is a strong advantage. You can decide to send files related to biomarker research experience to your R&D labs, files related to compound safety to your pre-clinical lab, …
We can definitively say that semantic indexing of datasets during an exchange of Intellectual Property is a true advantage in term of quickness, efficiency and maximize of the benefit!

Gold Sponsor, exhibitor at #PLA2020 will also run a workshop >> see more about DEXSTR Inquiro: different ways to reveal Insights from your data
Erwan David, Chief Technology Officer at Dexstr
Erwan holds degrees in molecular biology, genomics, and bioinformatics. For more than 12 years, he has managed bioinformatics projects for major pharmaceutical groups. At the start of his career, he redesigned chemical compound logistics from robotic control to multi-site synchronization. He later put in place an Enterprise Data Warehouse (multiple terabytes of chemical entities and biological results).

Stéphane Rouillè, Service Delivery Director at Dexstr
Stéphane joined DEXSTR in early 2018 and manages the company’s Consulting team composed of Solution Engineers and Solution Architects. Formerly, Stéphane served as Engagement & Project Manager at PTC for 6 years. He also held Project Management positions in pharmaceutical industries at Pierre Fabre & Sanofi for more than 9 years. He started his career at Genoplante, a public Bioinformatics resource center for 2 years.
Latest Posts
Key Topics of the PLA2024India
PLA2024India, 5th edition, promises a programme full of interactions and discussions. 4 focused sessions and 2 training workshops The main theme of #P
14 May 2024
Press Release: PLA® Conferences to partner with IA-Meetings for its 5th Indian Edition.
The Paperless Lab Academy® (PLA) is a leading conference about digital transformation of laboratory and quality processes. Above all, it is about mas
08 April 2024
The #PLA2024Europe programme aimed to highlight the importance of the human factor in digital transformation with several presentations and panel disc
19 March 2024