
Advocating for FAIR plus Q to bring Data Quality and FAIR together

A recent publication advocating for FAIR plus Q to bring Data Quality and FAIR together has caught our attention. It brings examples of FAIR implementations at two mayor pharma sites and a very interesting reflexion about the direct impact of FAIRification on data quality. Reference: I. Harrow et al., Drug Discovery Today (2022)
The Pharma industry has started to embrace the FAIR principles. With considerable progress, the transformative shift from an application-centric to a data-centric perspective remains very much a work in progress on the ‘FAIR journey. It is quite surprising that the FAIR and the Data Quality communities seem to be rather disconnected. Interestingly, the obvious relationship between FAIR data and Data Quality has not been considered so far. In this review, the authors show how FAIR implementation metrics, maturity indicators, can be deployed alongside assessment of data quality. This combination of FAIR and Quality implementation is likely to maximise the value of data generated from research, clinical trials, and real-world healthcare data, which are essential for the discovery and development of new medical treatments.
Many unresolved challenges are to be tackled by the FAIRification efforts in the life science industry. A crucial challenge involves not only building a technical infrastructure, but, more importantly, also harmonising the needs of multiple, diverse stakeholders. This includes training and managing the necessary cultural change, within an organisation and beyond, to the network of suppliers, regulators, stakeholders, and, ultimately, patients.
The adoption of the FAIR data principles at scale has led to a substantial transformation of the data management value chain in the life science Industries. This has resulted in building strategic roadmaps to drive digitalisation, creating highly connected and analytics-ready data sets. Many biopharma companies have implemented a significant number of tactical and operational projects to demonstrate the feasibility, practical impact, and business value of data FAIRification.
Two example case studies from Roche and AstraZeneca follow.
FAIR implementation at Roche
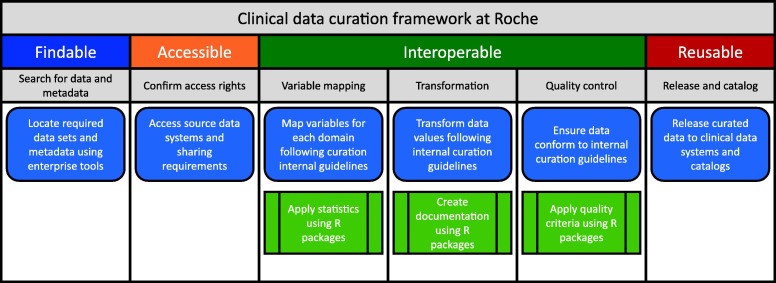
A wealth of clinical trial data has been collected by Roche over several decades across many therapeutic areas. In 2017, a collaborative, cross-functional (research and product development) program was launched to transform the data management practices and corporate culture of the company to accelerate the generation of meaningful scientific insights through FAIR and shared data. In addition, a significant investment in tools, technologies, and semantic infrastructure has been made to support the transformation. Although the long-term goal is to FAIRify all data sets, the company embraced a ‘learn-by-doing’ approach by launching a series of use cases prioritized by a board of scientists taking small chunks of data to answer specific scientific questions. By doing so, issues and challenges associated with the FAIRification process of legacy data were identified. Through these initial projects, a deeper understanding of how to improve and build the ecosystem of the company to make data FAIR at scale was achieved. It was found to be crucial to learn how to foster a ‘data citizen’ mindset within the organization.
FAIR implementation at AstraZeneca
Competitive intelligence, clinical study design, and translational medicine efforts have been the primary benefactors of data FAIRification efforts at AstraZeneca. Within the Oncology Translational Medicine Therapeutic Area of AstraZeneca, FAIR data implementation has focused on scientific use cases as a way to encourage greater data stewardship and reuse while solving key scientific challenges.
Few fundamental building blocks needed to be established, including implementing a persistent identifier policy,determining reference data sources as a backbone, and coalescing around a small number of domain vocabularies.19 This helped to set up the Findability and Interoperability principles.
 The basic URI structure follows a template in Backus-Naur Form (BNF): SCHEME PURPOSE FUNCTION DOMAIN ‘/’ (SCHEMA ‘/’ CONCEPT (EXT)* | CATEGORY (‘/’ SOURCE)* (‘/’ TOKEN)+ (EXT) + )
The basic URI structure follows a template in Backus-Naur Form (BNF): SCHEME PURPOSE FUNCTION DOMAIN ‘/’ (SCHEMA ‘/’ CONCEPT (EXT)* | CATEGORY (‘/’ SOURCE)* (‘/’ TOKEN)+ (EXT) + )
This URI structure has the terms and definitions shown in the figure.
For example, an identifier for a clinical study with the short title CP200, originating from the Biomarker Data Mining (BDM) system, would be constructed
Benefits for implementation of FAIR principles
Implementing the FAIR principles as a corporate data management strategy results in multiple improvements including the possibility for robotics and process automation through machine readability (of data and metadata), which will enable reuse and scalability. The entire process of running data through the value chain from acquisition, semantic alignment, integration and on to analytics to generate insights will become streamlined and, as a result, more effective. Data wrangling activities to make data ready for analysis will be minimised. Scientific queries will be answered more rapidly in an ad hoc and flexible manner. As a consequence, time-to-value will be significantly reduced, productivity will increase and drug R&D can be accelerated. The gains for the biopharma sector will be significant, including but not limited to: accelerating innovation owing to availability of FAIR data for primary use and secondary reuse; reducing the time from drug discovery to market value by shortening clinical trials; developing more-segmented or -personalised medicines by exploiting FAIR real-word data to match best treatment to relevant patient cohorts; and enabling data sharing and collaborations across institutions and companies. See full article Implementation and relevance of FAIR data principles in biopharmaceutical R&D
The FAIR Guiding Principles
The FAIR Data Principles were designed to ensure that all digital resources can be Findable, Accessible, Interoperable, and Reusable by machines. The Principles act as a guide to the kinds of behaviours that researchers and data stewards should increasingly expect from digital resources. See introduction to FAIR Principles presentation at last #PLA2019 edition
Findable:
F1. (meta)data are assigned a globally unique and persistent identifier
F2. data are described with rich metadata (defined by R1 below)
F3. metadata clearly and explicitly include the identifier of the data it describes
F4. (meta)data are registered or indexed in a searchable resource
Accessible:
A1. (meta)data are retrievable by their identifier using a standardized communications protocol
A1.1 the protocol is open, free, and universally implementable
A1.2 the protocol allows for an authentication and authorization procedure, where necessary
A2. metadata are accessible, even when the data are no longer available
Interoperable:
I1. (meta)data use a formal, accessible, shared, and broadly applicable language for knowledge representation.
I2. (meta)data use vocabularies that follow FAIR principles
I3. (meta)data include qualified references to other (meta)data
Reusable:
R1. meta(data) are richly described with a plurality of accurate and relevant attributes
R1.1. (meta)data are released with a clear and accessible data usage license
R1.2. (meta)data are associated with detailed provenance
R1.3. (meta)data meet domain-relevant community standards
The FAIR Principles are aspirational, in that they do not strictly define how to achieve a state of “FAIRness”. They describe a continuum increasingly rich (meta)data features, attributes, and behaviors that move a digital resource closer to that goal and support the automated discovery and reuse of important data resources. see full article: Evaluating FAIR maturity through a scalable, automated, community-governed framework
Those articles are developing on initiatives started and now maturing in the Life Science and most precisely Biopharmaceutical industry. However, the FAIR principles and the goals to be achieved by implementing them are to be considered nowadays by any other industries generating massive number of scientific data every day.
In conclusion, there should be more profound reflexions when initiating Paperless projects, digital transformation journeys. Looking back to your own data life cycle and designing first your data workflow
Latest Posts
Key Topics of the PLA2024India
PLA2024India, 5th edition, promises a programme full of interactions and discussions. 4 focused sessions and 2 training workshops The main theme of #P
14 May 2024
Press Release: PLA® Conferences to partner with IA-Meetings for its 5th Indian Edition.
The Paperless Lab Academy® (PLA) is a leading conference about digital transformation of laboratory and quality processes. Above all, it is about mas
08 April 2024
The #PLA2024Europe programme aimed to highlight the importance of the human factor in digital transformation with several presentations and panel disc
19 March 2024